PCのカメラから人物を推定してその物体の座標をMQTTで送るプログラムを作成します。
開発環境
WindowsPC
- PC: Win11
- カメラ:PC内蔵HD
- Python仮想環境管理 venvで構築
- エディタ: VS Code
プロジェクト環境の構築
VS codeでフォルダを作成

ライブラリやモデルのインストール

USBカメラの映像取得
まずは、OpenCVを使用してカメラ映像を取得します。
app-001.py
import cv2
cap = cv2.VideoCapture(0) # USBカメラを選択
while True:
ret, frame = cap.read()
if not ret:
break
cv2.imshow('Camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 'q'で終了
break
cap.release()
cv2.destroyAllWindows()
>python app-001.py
ソースを実行
人物を検出しボックスの中心座標と確度を表示するアプリ
カメラの映像から、YOLOを使って物体を検出。人物のみを検出し、その中心座標と物体認識の確度を表示させるように修正。
import cv2
import torch
# YOLOv5 のモデルをロード
model = torch.hub.load("ultralytics/yolov5", "yolov5s", pretrained=True)
# USBカメラを起動
cap = cv2.VideoCapture(0) # USBカメラを選択
if not cap.isOpened():
print("カメラが開けませんでした。")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("フレームの取得に失敗しました。")
break
# YOLOv5 でオブジェクトを検出
results = model(frame)
# 検出結果を取得
df = results.pandas().xyxy[0] # pandas DataFrame で結果を取得
for _, row in df.iterrows():
x1, y1, x2, y2, conf, cls = row["xmin"], row["ymin"], row["xmax"], row["ymax"], row["confidence"], row["name"]
# **person以外を除外**
if cls != "person":
continue
# 中心座標を計算
x_center = int((x1 + x2) / 2)
y_center = int((y1 + y2) / 2)
# コンソールに情報を表示
print(f"Detected {cls} at center: ({x_center}, {y_center}), confidence: {conf:.2f}")
# バウンディングボックスを描画
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# **中心座標に赤い点を描画**
cv2.circle(frame, (x_center, y_center), 5, (0, 0, 255), -1)
# **映像の中にオブジェクト名、確度、座標を表示**
text = f"{cls} ({x_center}, {y_center}) {conf:.2f}"
cv2.putText(frame, text, (x_center + 10, y_center - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2)
# 映像を表示
cv2.imshow('Camera', frame)
# 'q' を押したら終了
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# リソースの解放
cap.release()
cv2.destroyAllWindows()
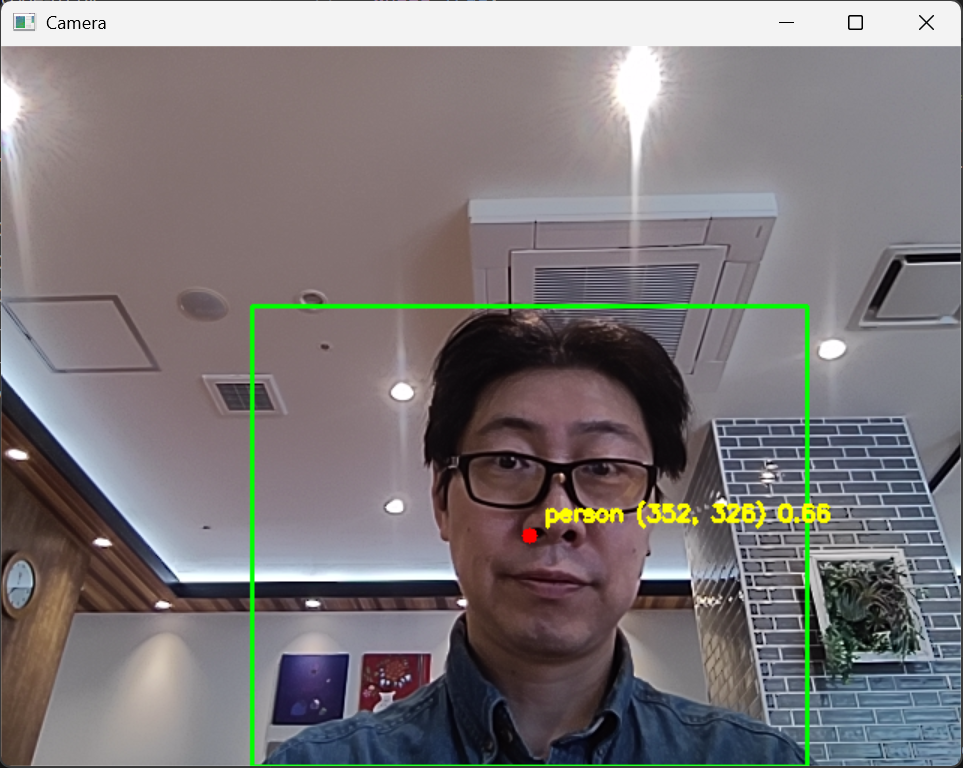
以上のように、人物を検出、中心座標とその確度を表示することができました。
次はPythonでMQTTを送るコードを作成します。